1. 联邦学习与分布式机器学习的区分
在将隐私保护计算技术应用到机器学习场景的过程中,催生了诸多技术概念,比如联邦学习。提到联邦学习,就不得不提分布式机器学习,形式上来看两者都是在处理分散的数据和模型,但两者又存在着很明显的区别。
首先在场景上,分布式机器学习更多的是在数据中心或集群的范围内的分布式,侧重于并行处理,以集群规模的扩展来增大内存,增加处理器的数目,最终来提高模型训练的速度和计算的吞吐率,联邦学习则更多的是面向地理分布式的场景;此外两者最大的不同还是在隐私安全的保护上,分布式机器学习并不考虑隐私保护,但对联邦学习来说,隐私保护是重点。
2. 深度学习软件生态
回顾人工智能框架的发展历史,从前端的编程接口,到结合编译优化的优化器,再到面向架构的高效计算核心的自动生成,目前的深度学习软件生态逐步形成了一个层次分明、功能强大的系统软件栈。以机器学习框架为代表的系统软件的发展,对领域的成功起到了十分重要的作用,总的来说体现在如下两个方面:
.png)
(1)灵活易用的编程接口:为了提高编程的友好度,主要有两种思路:
第一,选择灵活易用的编程语言,比如Python,这是主流的深度学习框架Tensorflow/Pytorch成功的经验,早期的Caffe使用Protobuf来定义模型,还有很多框架选择了DSL或者其他的语言,相比之下,借助于Python的优点,Tensorflow/Pytorch,不论在科研领域还是在工业界都保持了绝对的优势。
第二种,依托强大的开源生态,比如谷歌最新推出的框架JAX完全继承了Numpy的接口,使得算法科学家在使用上可以做到无缝切换;
此外,Pytorch主打命令式的编程,调试友好,编程直观;而Tensorflow则面向全局的性能优化,主打声明式的编程,即首先定义模型的数据流图,然后再编译运行。
最后是自动微分,自动求导已经是目前深度学习框架的标配。
(2)高性能的系统设计:
深度学习任务的一大特点,就是面对大数据和高复杂度的计算,所以如何优化计算性能是一个很重要的内容。从系统角度来说,可以分为单机和分布式两个方面的设计:
-
单机优化:针对多样化的硬件架构设计实现高效的计算核心,典型工作是以TVM为代表的自动优化的工作,单机优化的另一个关键点,是结合深度模型的数据流图这一中间表达,进行诸如算子融合的编译优化,这个方面的代表则是Tensorflow生态的XLA;
-
分布式设计:经典设计是参数服务器架构,优点是设计简单,对异步友好,容错和可扩展性高。同时针对深度学习模型训练任务的特点,像数据并行、模型并行、混合并行等分布式的并行策略,也被广泛的研究和应用到实际的系统中来。
3. 隐私保护框架的设计
如何借助已有深度学习软件栈设计隐私保护框架?PySyft和Tensorflow-Encrypted分别从Pytorch的生态和Tensorflow的生态给出了答案。
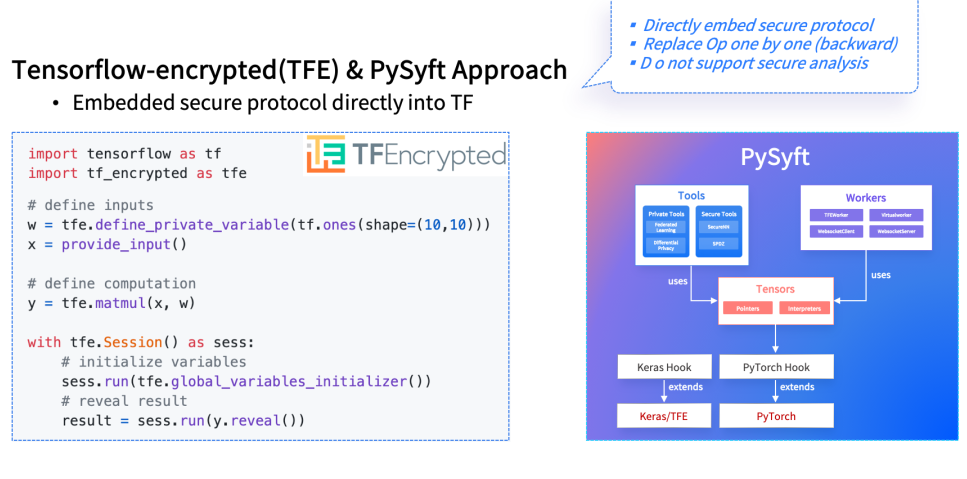
图片来源:https://github.com/OpenMined/PySyft/tree/syft_0.2.x
例如,用TFE实现的一个矩阵乘案例,通过深度绑定了秘密分享技术(即Secret sharing),从使用形式上做到了和编写普通的模型基本无异,但受限于Secret sharing,它需要一个可信的第三方。同时在内部的实现上,TFE采取的是算子替换的策略,即replace op-by-op的方式,这意味着为支持一个新的算子,同时需要添加它的正向和反向的实现。PySyft在后端上做了扩展,同时支持基于秘密分享以及同态加密的技术,但它基本上仍然采取的是算子替换的策略。除此之外,基于国产开源框架——PaddleFL和FATE,也已经有很多针对性的工作来支持隐私保护或者联邦学习的需求。
_1.png)
4. 现有隐私保护系统方案仍有待提升
现有的隐私保护系统方案,无论是基于已有深度学习框架的成熟生态,还是重新设计的专用系统都仍有待提升,主要体现在以下三个方面:
第一,目前大部分的方案采取的都是一种紧耦合的设计,无论是在算子的层次,即把普通的算子替换成某种加密技术实现的算子,还是在算法的层次,直接在特定的安全技术下封装一个特定的算法,以供高层调用,都是将算法的逻辑和安全协议紧密绑定,意味着同一个模型选用不同的密码学方案将对应完全不同的实现,最终导致很多高层的模块(如通用优化)重复设计;
第二,安全性的支持较弱,这与其在隐私保护机器学习系统中的重要性,不相匹配,这里的安全性需要从以下两个方面考虑:首先是可分析,即全数据流图全流程的信息要可控透明,而不是将分析仅仅局限在一个算子的范围;第二点是可量化,将系统提供的安全性量化有助于评估系统,统一标准;
第三,性能的有待提升,密码学技术的使用,把计算复杂度提升到了一个新的水平,所以性能需放到系统设计的首要考虑因素,比如不同密码学算子需要不同的优化方案,单一的策略欠佳,需要有针对性的设计混合优化策略,同时共享高层的设计,以实现通用的全局优化。